명령어 수준 병렬성(instruction-level parallelism, ILP)
파이프라이닝은 명령어 사이의 병렬성을 이용하는 기법이다. 병렬 수준을 높이기 위한 방법은 다음 두 가지가 있다.
1. 파이프라인 깊이를 증가시켜 더 많은 명령어들을 중첩시키는 방법
2. 매 파이프라인 단계에서 다수의 명령어를 내보내는 방법
다중 내보내기 Multiple Issue : 다수의 명령어를 내보내어 동시에 둘 이상의 명령어를 처리한다.
- 다중 내보내기 (multiple issue) 방법은 매 단계마다 다수의 명령어를 내보내면 명령어 실행 속도가 클럭 속도보다 빨라질 수 있다. 즉 CPI가 1보다 작아질 수 있어 명령어 1개를 실행하는 속도가 클럭 주기보다 빠른 것이다.
정적 다중 내보내기 static multiple issue vs 동적 다중 내보내기 dynamic multiple issue
정적 다중 내보내기: 많은 결정들이 실행하기 전에 컴파일러에 의해 이루어지는 다중 내보내기 프로세서 구현 방법
동적 다중 내보내기: 많은 결정들이 실행 중에 프로세서에 의해 이루어지는 다중 내보내기 프로세서 구현 방법
다중 내보내기의 고려사항
1. 명령어로 issue slot 채우기
- 주어진 클럭 사이클 내에서 얼마나 많은 명령어를 내보낼 것인가? 어떤 명령어를 내보낼 것인가?
정적 처리에서는 컴파일러가 결정하지만 동적 처리에서는 컴파일러가 일부 도와주고 실행에서 대부분 결정을 한다.
2. 데이터 해저드와 제어 해저드의 처리
- 정적 내보내기 프로세서에서는 데이터 해저드와 제어 해저드의 전부 또는 일부를 컴파이러가 정적으로 처리한다. 대부분의 동적 내보내기 프로세서는 시행 시간에 동작하는 하드웨어 기법을 이용하여 해저드를 없애려고 한다.
정적 다중 내보내기 static multiple issue
정적 내보내기 프로세서에서 한 사이클에서 내보내는 명령어의 묶음을 내보내기 패킷이라고 한다. 같이 내보낼 수 있는 명령어의 조합에는 제한이 있다.
RISC-V의 예
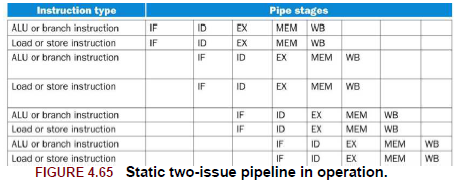
정적 다중 내보내기의 예로 두 명령어를 동시에 내보낼 수 있다. 한 명령어는 ALU 계산 혹은 분기 명령어이고 한 명령어는 데이터 전송 명령어(Load, Store)가 될 수 있다. 두 명령어 중 하나를 사용할 수 없다면 nop로 대체될 것이다.
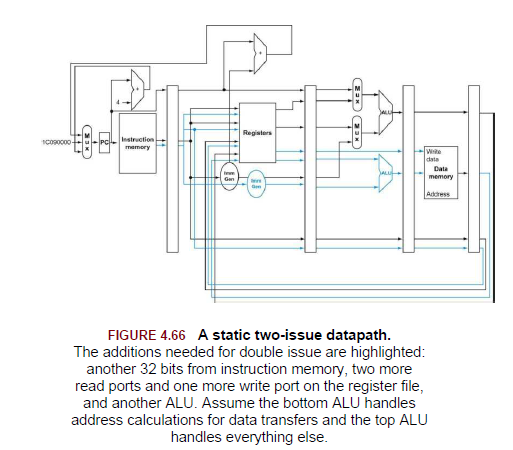
두 명령어를 같이 실행하기 위해 추가적으로 필요한 것은 레지스터 파일의 추가 포트이다. 한 사이클에 ALU 연산을 위해 두 레지스터를 읽어야되고 저장 명령어를 위해 두 레지스터를 더 읽어야 되며 쓰기 포트도 추가되어한다. 또한 유효 주소를 계산하기 위해서 독자적인 덧셈기도 필요하다. 추가 하드웨어 자원 없이는 두 명령어 실행에서 구조적 해저드가 발생하기 때문이다.
순환문 펼치기
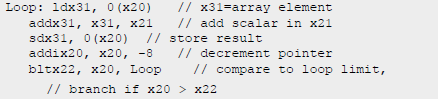
위 루프문에서 첫 3 명령어에 데이터 종속성이 존재(x31)하고 마지막 두 개의 명령어에서도 데이터 종속성(x20)이 존재한다.

두 명령어에 대해 정적 내보내기 기법으로 위와 같이 스케줄링하면 5개의 명령어를 실행하는데 4 클럭 사이클이 걸린다. 2개의 명령어를 동시에 내보낼 경우 이상적인 경우 0.5 CPI가 기대되지만 실제로는 0.8 밖에 성능이 나오지 않는다.
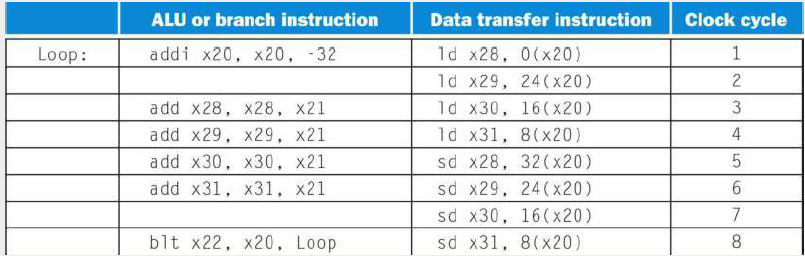
순환문 펼치기는 서로 다른 반복문에서 실행되는 명령어를 중첩시킨다. 중간 중간에 명령어를 추가하여 불필요한 순환문 오버헤드를 제거한다. 순환문은 4개의 ld, add, sd와 한 개씩의 addi, blt를 가지게 된다. 예에서는 원래 시작 주소 값과 4개의 오프셋을 이용하여 배열 값 중 4개에 관한 명령어를 펼치기 하여 파이프라이닝 한다.
펼치기 과정 중 도입된 x28, x29, x30 레지스터들, 레지스터 재명명(register renaming)은 컴파일러가 코드를 유연하게 스케줄링하고 데이터 종속성을 없앤다.
동적 다중 내보내기 dynamic multiple issue
동적 다중 내보내기를 실행하는 프로세서는 수퍼스칼라(superscalar)라고도 한다. 제일 간단한 수퍼스칼라 프로세서는 명령어를 순차대로(in-order) 내보내고 주어진 클럭 사이클에 몇 개의 명령어를 내보낼지 결정한다.
많은 수퍼스칼라 프로세서는 동적 파이프라인 스케줄링(dynamic pipeline scheduling)을 포함한다.
ld x31, 0(x21)
add x1, x31, x2
sub x23, x23, x3
andi x5, x23, x20
여기서 sub 명령어는 당장 실행될 준비가 되어 있어도 ld에 의해 1 사이클 지연되고 또한 메모리에 적재하는 시간에 따라 더 오래 걸릴 수 있다. 동적 파이프 라인 스케줄링은 지연을 피할 수 있도록 명령어 실행 순서를 바꾸는 것에 대하여 하드웨어를 지원한다. (sub 명령어를 맨 위로 올리거나 등등)
동적 파이프라인 스케줄링
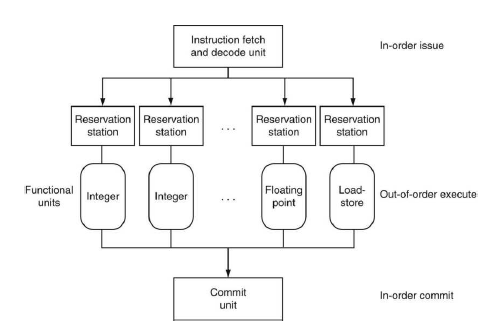
동적 파이프라인 스케줄링은 다음에 어떤 명령어를 실행할 것인가를 선택하고 지연을 피하기 위해 명령어들을 재정렬할 수 도 있다. 그런 프로세서의 파이프라인은 3개의 주요 유닛으로 나누어지는데, 명령어 인출 및 내보내기 유닛, 다수의 기능 유닛(functional units), 결과 쓰기 유닛(commit unit)으로 나누어진다.
첫 번째 유닛은 명령어를 인출 및 해독하여 각각의 명령어를 실해 단계의 해당 기능 유닛에 보낸다. 각 기능 유닛은 대기 영역이라 불리는 버퍼를 가지고 있는데 이 대기 영역(reservation station)은 피연산자와 연산자를 가지고 있다.
모든 피연산자가 버퍼에 준비되고 기능 유닛이 실행할 준비가 되면 결과가 계산된다. 결과가 완료되면 결과는 결과 쓰기 유닛뿐만 아니라 특정한 결과를 기다리고 있는 대기 영역에 보내진다.
결과 쓰기 유닛에서는 결괏값을 버퍼에 두었다가 안전할 때 결과값을 메모리나 레지스터 파일에 쓴다. 이러한 버퍼를 재정렬 버퍼(reorder buffer)라고 부르고 전방 전달 회로가 정적 스케줄 파이프라인에서 했던 것처럼 피연산자들을 다른 대기 영역으로 제공해준다.
두 버퍼링은 레지스터 재명명의 한 종류이다. 개념적인 동작 방식은 다음과 같다.
1) 인출되어 해독된 명령어는 해당 기능 유닛의 대기 영역으로 복사된다. 필요로 하는 피연산자가 레지스터 파일이나 재정렬 버퍼에 있다면 대기 영역으로 복사해 온다. 명령어는 모든 피연산자와 실행 유닛이 사용 가능해질 때까지 대기 영역에 버퍼링 된다.
2) 만약 피연산자가 레지스터 파일이나 재정렬 버퍼에 없다면 기능 유닛에 의해 생성될 때까지 기다려야 한다. 결과를 만들어낼 기능 유닛을 추적하여 결괏값이 계산되는 즉시, 레지스터 쓰기 없이 대기 영역에 복사되도록 한다.
동적 스케줄 파이프라인에서 프로세서는 프로그램의 데이터 흐름 순서를 바꾸지 않는 범위 내에서 명령어의 실해 순설을 바꿀 수 있다. 이러한 실행 형태를 비순차 실행(out-of-ordere execution)이라고 한다.
순차 실행되는 유닛들, 명령어 인출 및 해독 유닛이 순서대로 명령어들을 내보내고 쓰기 유닛은 프로그램 인출 순서대로 결과를 레지스터나 메모리에 써야 한다. 이러한 쓰기를 순차 결과 쓰기(in-order commit)이라고 한다.
기능 유닛들은 비순차 실행으로 자유롭게 명령들을 실행 가능하며 다른 명령어 인출과 쓰기 유닛은 순차적 방식을 택하나. 동적 스케줄링은 분기 예측과 같이 하드웨어 기반의 추정을 포함하여 확장한다.
최신 고성능 마이크로프로세서는 여러 개의 명령어를 동시에 내보낼 수 있지만 그런 내보내기 속도를 유지하는 것은 매우 어렵다. 3개 이상 명령어 내보내기를 유지하는 응용은 매우 드문데 이유는 다음과 같다.
1) 파이프라인 성능의 주요 병목은 없앨 수 없는 종속성 때문에 생긴다.
- 많은 동의어가 있는 포인터는 종속성을 예측을 어렵게 한다. 반대로 배열 접근은 컴파일러가 종속성이 없다고 확신할 수 있다.
2) 메모리 계층 구조에서 손실이 파이프라인을 가득 채우지 못하게 한다.
참고 : Computer Organization and Design RISC-V edition
'Computer Science 기본 지식 > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] 11. 캐시 성능 측정 및 향상 (0) | 2021.04.26 |
|---|---|
| [컴퓨터 구조] 10. 메모리 기술 (0) | 2021.04.25 |
| [컴퓨터 구조] 8. 파이프 라인 해저드 (0) | 2021.04.19 |
| [컴퓨터 구조] 7. 파이프 라인된 데이터 패스 (0) | 2021.04.18 |
| [컴퓨터 구조] 6. 명령어 파이프라이닝 (0) | 2021.04.18 |