정적 메모리 풀을 설계해본다.
정적 메모리 풀
정적 메모리 풀은 조각의 크기가 정해진 메모리를 배열처럼 사용하는 것으로 조각의 메모리 주소가 연속적이기 때문에 캐시에 유리하다. 또한 여러번 할당에서 한번 블록을 생성하는 것으로 줄이므로 동적할당 발생하는 비용을 줄일 수 있다.
임의의 타입 T에 배수만큼 큰 힙 메모리를 할당하여 T* pObject = new T;를 통해 동적할당할때 마다 미리 할당한 메모리 블록으로 부터 한 조각을 T 타입으로 초기화하여 반납하고 delete pObject;를 할때 다시 해당 조각을 반납한다.

인덱스를 이용한 요청과 반납 방식

조각 마다 인덱스를 부여하고 해당 인덱스는 큰 블록을 생성할 때 만들어준다. 메모리 요청시 현재 꺼내야하는 인덱스를 가지고 메모리 블록과 블록에서 몇번째 조각인지 알아내어 메모리를 준다.
반납시 메모리 주소를 참고하여 인덱스 정보를 T*에 따로 저장할 필요없이 T*의 메모리 주소를 바탕으로 블록을 찾고 해당 블록에서 오프셋을 계산하여 인덱스를 알 수 있다.
필요한 자료구조
1. 메모리 블록을 담을 컨테이너
2. 인덱스를 담을 컨테이너
3. 현재 할당해야하는 조각 인덱스 번호
4. 현재 가질 수 있는 최대 조각 개수
5. 동기화
클래스 설계
해당 클래스를 상속받아 사용한다.
template<typename T, unsigned int ALLOC_BLOCK_NUM = 50>
class StaticMemoryPool
{
typedef unsigned int uint32;
typedef std::unique_ptr<char[]> MemoryBlock;
private:
static std::vector<MemoryBlock> m_vecMemBlocks;
static std::vector<uint32> m_vecIndex;
static uint32 m_NumOfChunks;
static uint32 m_CurChunkIndex;
static CriticalSection m_tMutex;
protected:
virtual ~StaticMemoryPool()
{
}
//...new 오버로딩
해당 클래스에서 new를 오버로딩하여 메모리를 얻는 방법을 구현한다.
마지막에 placement new를 이용하여 해당 T 타입 객체를 초기화해준다.
static void* operator new(size_t allocLength)
{
CS_LOCK_GUARD tLockGuard(m_tMutex);
// 사용할 수 있는 조각이 없다면
if (m_CurChunkIndex == m_NumOfChunks)
{
const uint32 NextChunkNum = m_NumOfChunks + ALLOC_BLOCK_NUM;
// 인덱스 어레이 확장
m_vecIndex.resize(NextChunkNum);
// 인덱스 할당
for (uint32 i = m_NumOfChunks; i < NextChunkNum; ++i)
{
m_vecIndex[i] = i;
}
// 메모리 블록 확장
m_vecMemBlocks.emplace_back(new char[ALLOC_BLOCK_NUM * sizeof(T)]);
m_NumOfChunks = NextChunkNum;
}
// 블록과 블록 안에서의 인덱스를 구한다.
uint32 BlockIndex = m_vecIndex[m_CurChunkIndex] / ALLOC_BLOCK_NUM;
uint32 ChunkIndex = m_vecIndex[m_CurChunkIndex] % ALLOC_BLOCK_NUM;
++m_CurChunkIndex;
char* pMemory = m_vecMemBlocks[BlockIndex].get();
// placement new
return ::new (pMemory + ChunkIndex * sizeof(T)) (T);
}
delete 오버로딩
메모리 주소를 참고하여 메모리 블록 컨테이너를 탐색하여 오프셋이 유효한 메모리 블록을 선형 탐색으로 찾는다.
(정렬하고 std::upper_bound를 사용해보았으나 메모리 블록이 많지 않다면 간단한 선형 탐색이 훨씬 빠르더라..)
static void operator delete(void* pMemory)
{
CS_LOCK_GUARD tLockGuard(m_tMutex);
int BlockIndex = 0, ChunkIndex = 0;
for (const auto& pBlock : m_vecMemBlocks)
{
ChunkIndex = (int)(reinterpret_cast<T*>(pMemory) - reinterpret_cast<T*>(pBlock.get()));
if (ChunkIndex >= 0 && ChunkIndex < ALLOC_BLOCK_NUM)
break;
++BlockIndex;
}
m_vecIndex[--m_CurChunkIndex] = BlockIndex * ALLOC_BLOCK_NUM + ChunkIndex;
}
전체 코드
StaticMemoryPool.h
#pragma once
#include <Windows.h>
#include <cstdlib>
#include <cstdio>
#include <memory>
#include <vector>
#include <cassert>
#include <unordered_map>
#include <algorithm>
#include <mutex>
#include "CriticalSection.h"
template<typename T, unsigned int ALLOC_BLOCK_NUM = 50>
class StaticMemoryPool
{
typedef unsigned int uint32;
typedef std::unique_ptr<char[]> MemoryBlock;
private:
static std::vector<MemoryBlock> m_vecMemBlocks;
static std::vector<uint32> m_vecIndex;
static uint32 m_NumOfChunks;
static uint32 m_CurChunkIndex;
static CriticalSection m_tMutex;
protected:
virtual ~StaticMemoryPool()
{
}
public:
static void* operator new(size_t allocLength)
{
CS_LOCK_GUARD tLockGuard(m_tMutex);
// 사용할 수 있는 조각이 없다면
if (m_CurChunkIndex == m_NumOfChunks)
{
const uint32 NextChunkNum = m_NumOfChunks + ALLOC_BLOCK_NUM;
// 인덱스 어레이 확장
m_vecIndex.resize(NextChunkNum);
// 인덱스 할당
for (uint32 i = m_NumOfChunks; i < NextChunkNum; ++i)
{
m_vecIndex[i] = i;
}
// 메모리 블록 확장
m_vecMemBlocks.emplace_back(new char[ALLOC_BLOCK_NUM * sizeof(T)]);
m_NumOfChunks = NextChunkNum;
}
// 블록과 블록 안에서의 인덱스를 구한다.
uint32 BlockIndex = m_vecIndex[m_CurChunkIndex] / ALLOC_BLOCK_NUM;
uint32 ChunkIndex = m_vecIndex[m_CurChunkIndex] % ALLOC_BLOCK_NUM;
++m_CurChunkIndex;
char* pMemory = m_vecMemBlocks[BlockIndex].get();
// placement new
return ::new (pMemory + ChunkIndex * sizeof(T)) (T);
}
static void operator delete(void* pMemory)
{
CS_LOCK_GUARD tLockGuard(m_tMutex);
int BlockIndex = 0, ChunkIndex = 0;
for (const auto& pBlock : m_vecMemBlocks)
{
ChunkIndex = (int)(reinterpret_cast<T*>(pMemory) - reinterpret_cast<T*>(pBlock.get()));
if (ChunkIndex >= 0 && ChunkIndex < ALLOC_BLOCK_NUM)
break;
++BlockIndex;
}
m_vecIndex[--m_CurChunkIndex] = BlockIndex * ALLOC_BLOCK_NUM + ChunkIndex;
}
};
template<typename T, unsigned int ALLOC_BLOCK_NUM>
CriticalSection StaticMemoryPool<T, ALLOC_BLOCK_NUM>::m_tMutex = {};
template<typename T, unsigned int ALLOC_BLOCK_NUM>
std::vector<std::unique_ptr<char[]>> StaticMemoryPool<T, ALLOC_BLOCK_NUM>::m_vecMemBlocks = {};
template<typename T, unsigned int ALLOC_BLOCK_NUM>
std::vector<unsigned int> StaticMemoryPool<T, ALLOC_BLOCK_NUM>::m_vecIndex = {};
template<typename T, unsigned int ALLOC_BLOCK_NUM>
unsigned int StaticMemoryPool<T, ALLOC_BLOCK_NUM>::m_NumOfChunks = 0;
template<typename T, unsigned int ALLOC_BLOCK_NUM>
unsigned int StaticMemoryPool<T, ALLOC_BLOCK_NUM>::m_CurChunkIndex = 0;동기화에 사용된 CriticalSection
#pragma once
#include <Windows.h>
class CriticalSection
{
public:
CRITICAL_SECTION m_Mutex;
public:
CriticalSection()
{
InitializeCriticalSection(&m_Mutex);
}
~CriticalSection()
{
DeleteCriticalSection(&m_Mutex);
}
};
class CS_LOCK_GUARD
{
private:
CRITICAL_SECTION* m_Lock;
public:
CS_LOCK_GUARD(CriticalSection& lock)
:
m_Lock(&lock.m_Mutex)
{
EnterCriticalSection(m_Lock);
}
~CS_LOCK_GUARD()
{
LeaveCriticalSection(m_Lock);
}
};
테스트
정적 메모리 풀을 사용하면 빠른지 테스트해본다. 결론부터 말하면 약간 더 빠르긴 하나 메모리 사용 패턴이나 사용 스레드 개수에 따라 영향을 받고 특히 동기화에 따른 병목이 유의미하게 큰 것으로 나타났다.
비교 클래스
메모리 풀을 상속하한 클래스와 일반 클래스를 사용한다.
class SmartObject : public StaticMemoryPool<SmartObject, 50>
{
private:
char Name[256];
public:
SmartObject() { };
~SmartObject() { };
};
class NormalObject
{
private:
char Name[256];
public:
NormalObject() { };
~NormalObject() { };
};
패턴 기반 메모리 할당 및 해제
다음과 같은 톱날 패턴으로 메모리 할당 해제가 일어날 때, 실제 사용 방식을 모방하기 위해 다음과 같은 패턴을 미리 만들어두고 할당 해제가 일어나도록한다. 테스트에서는 단순히 for문을 사용해서 인접한 메모리를 할당하고 해제하였지만 실제 상황에서는 메모리 할당과 해제가 임의의 주소에서 이루어지기 때문에 메모리 단편화와 같은 영향을 반영하기가 어렵다.
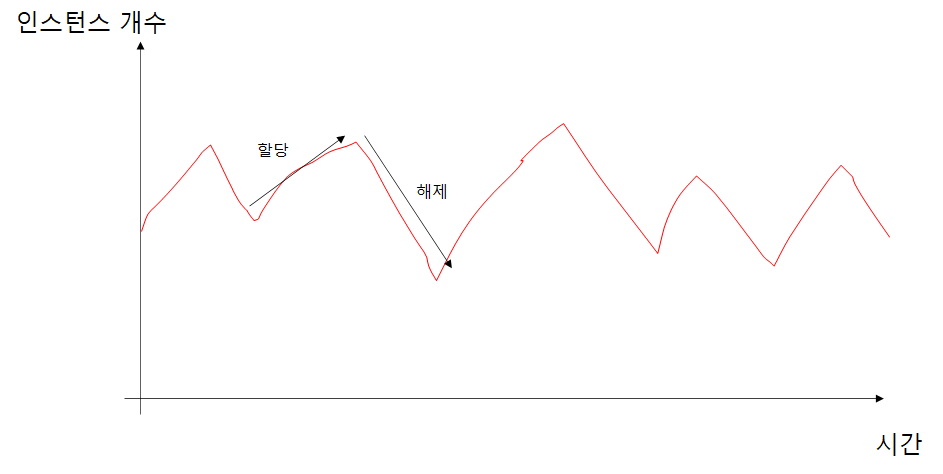
다중 스레드 사용
스레드를 여러개 생성하여 위 패턴을 바탕으로 동일한 작업을 수행한 시간을 합해준다. 이때 스레드를 만들고 모두 준비가 됐는지 알기 위해 이벤트 객체를 사용하여 동기화한다. 메모리 풀 사용과 사용하지 않음에 대해 한꺼번에 쓰레드를 사용하지 않고 차례차례 실행한다.
패턴 개수 변화
- 기본 블록당 인스턴스 50개
- 최대 인스턴스 카운트 100개 (패턴에서 최대로 사용하는 인스턴스 개수)
- 스레드 1개



- 스레드 하나를 사용할 경우 일반적으로 정적 메모리 풀을 사용하는 것이 유리하다.
- 락을 사용하지 않으면 더 큰 차이를 보일 것이다.
패턴 변화
- 기본 블록당 인스턴스 50개
- 패턴 개수 100000개
- 최대 인스턴스 개수를 바꾸어본다. (편차가 크다.)



- 인스턴스가 많아질 경우 해제시 메모리 블록을 탐색하는 비용이 증가한다. 이를 위해 조각마다 메모리 블록을 따로 저장하거나 기본 인스턴스 개수를 증가시켜 메모리 블록 개수를 줄이도록 한다.
스레드 개수 변화
- 기본 블록당 인스턴스 50개
- 최대 인스턴스 카운트 100개 (패턴에서 최대로 사용하는 인스턴스 개수)
- 패턴 개수 100000개



- 스레드 개수를 변화시키면서 작업 시간을 관찰해보니 동기화로 인한 병목의 영향이 큰 것으로 보인다.
전체 테스트 코드
#include <windows.h>
#include <crtdbg.h>
#include <iostream>
#include "StaticMemoryPool.h"
#include "PerformanceCounter.h"
using namespace std;
class SmartObject : public StaticMemoryPool<SmartObject, 50>
{
private:
char Name[256];
public:
SmartObject() { };
~SmartObject() { };
};
class NormalObject
{
private:
char Name[256];
public:
NormalObject() { };
~NormalObject() { };
};
static constexpr int MaxInstanceCount = 1000;
static constexpr int CaseCount = 100000;
static constexpr int ThreadCount = 1;
unsigned int Pattern[CaseCount] = {};
struct UserData
{
int Id;
double Result;
DWORD ThreadId;
};
HANDLE hWaitEvent;
HANDLE hThread[ThreadCount], hThreadReady[ThreadCount];
DWORD WINAPI CreateSmartObject(LPVOID lpParameter);
DWORD WINAPI CreateNormalObject(LPVOID lpParameter);
void Execute(LPTHREAD_START_ROUTINE Function, const char* FunctionName)
{
UserData ThreadInfo[ThreadCount] = {};
for (int i = 0; i < ThreadCount; ++i)
{
ThreadInfo[i].Id = i;
hThreadReady[i] = CreateEvent(NULL, TRUE, FALSE, NULL);
hThread[i] = CreateThread(NULL, NULL, Function, (LPVOID)&ThreadInfo[i], 0, &ThreadInfo[i].ThreadId);
}
WaitForMultipleObjects(ThreadCount, hThreadReady, TRUE, INFINITE);
cout << "Threads Are Ready" << endl;
SetEvent(hWaitEvent);
WaitForMultipleObjects(ThreadCount, hThread, TRUE, INFINITE);
double Result = 0.;
for (int i = 0; i < ThreadCount; ++i)
{
Result += ThreadInfo[i].Result;
}
cout << FunctionName << " Elapsed : " << 1000. * Result << "ms" << endl << endl;
for (int i = 0; i < ThreadCount; ++i)
{
CloseHandle(hThreadReady[i]);
CloseHandle(hThread[i]);
}
}
int main()
{
_CrtSetDbgFlag(_CRTDBG_ALLOC_MEM_DF | _CRTDBG_LEAK_CHECK_DF);
hWaitEvent = CreateEvent(NULL, TRUE, FALSE, NULL);
if (hWaitEvent == NULL)
return -1;
cout << "Pattern" << endl;
for (int i = 0; i < CaseCount; ++i)
{
Pattern[i] = min(MaxInstanceCount, (int) ((float)MaxInstanceCount * (float)rand() / (float)RAND_MAX));
if (i < 20)
{
cout << Pattern[i] << ", ";
}
}
cout << endl;
Execute(CreateSmartObject, "SmartObject");
Execute(CreateNormalObject, "NormalObject");
CloseHandle(hWaitEvent);
return 0;
}
DWORD WINAPI CreateSmartObject(LPVOID lpParameter)
{
PerformanceCounter Counter;
SmartObject* TempArray[MaxInstanceCount] = {};
UserData* pData = (UserData*)(lpParameter);
SetEvent(hThreadReady[pData->Id]);
WaitForSingleObject(hWaitEvent, INFINITE);
Counter.Tick();
int Current = 0;
for (int i = 0; i < CaseCount; ++i)
{
int Target = Pattern[i];
int Diff = Target - Current;
if (Diff == 0)
continue;
if (Diff > 0)
{
for (int k = Current; k < Target; ++k)
{
TempArray[k] = new SmartObject;
}
}
else
{
for (int k = Current - 1; k >= Target; --k)
{
delete TempArray[k];
}
}
Current = Target;
}
for (int i = 0; i < Current; ++i)
{
delete TempArray[i];
}
pData->Result = Counter.Toc();
return 0;
}
DWORD WINAPI CreateNormalObject(LPVOID lpParameter)
{
PerformanceCounter Counter;
NormalObject* TempArray[MaxInstanceCount] = {};
UserData* pData = (UserData*)(lpParameter);
SetEvent(hThreadReady[pData->Id]);
WaitForSingleObject(hWaitEvent, INFINITE);
Counter.Tick();
int Current = 0;
for (int i = 0; i < CaseCount; ++i)
{
int Target = Pattern[i];
int Diff = Pattern[i] - Current;
if (Diff == 0)
continue;
if (Diff > 0)
{
for (int k = Current; k < Target; ++k)
{
TempArray[k] = new NormalObject;
}
}
else
{
for (int k = Current - 1; k >= Target; --k)
{
delete TempArray[k];
}
}
Current = Target;
}
for (int i = 0; i < Current; ++i)
{
delete TempArray[i];
}
pData->Result = Counter.Toc();
return 0;
}'Advanced C++' 카테고리의 다른 글
| [C++] C++20 동시성 컨테이너를 사용하여 ThreadPool 설계하기 (0) | 2022.03.26 |
|---|---|
| [C++] 정규식 표현 std::regex으로 문자열 찾기 (0) | 2022.02.07 |
| [C++] 메모리 관리 (3) 주소 기반 초기화 placement new (0) | 2021.10.06 |
| [C++] 메모리 관리 (2) 힙 메모리 new/malloc/HeapAlloc/VirtualAlloc (2) | 2021.10.03 |
| [C++] 메모리 관리 (1) Windows 메모리 관리 (0) | 2021.10.03 |