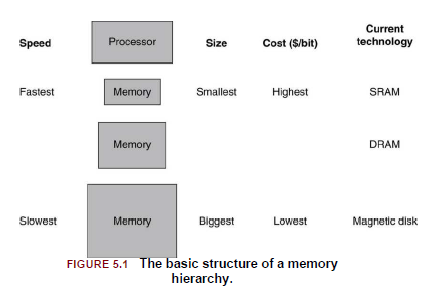
C++11에 도입된 std::promise와 std::future 객체를 알아본다. 약속 객체 (std::promise) 약속 객체는 주로 비동기적으로 실행되는 다른 쓰레드로 부터 계산된 값이나 예외를 저장할 수 있는 공간을 가지고 있다. 약속 객체가 쓰레드의 완료로 저장한 값을 전달하기 위해 미래 객체가 필요하고 미래 객체는 약속 객체에 의해 생성된다. 또한 약속 객체는 결과 전달을 한번만 하도록 설계되었다. 템플릿 정의 template class promise; // 기본 템플릿 template class promise; // 쓰레드간 객체를 통신하기위해 사용한다. template class promise; // 상태없는 이벤트를 통신하기위해 사용한다. - 템플릿 인수에 전달받을 값의 타입을 명시하여..